(This page was last modified on 2003/03/19 03:14:03 UTC)
| Block Diagram Of SQLite |
|---|
|
This document describes the architecture of the SQLite library. The information here is useful to those who want to understand or modify the inner workings of SQLite.
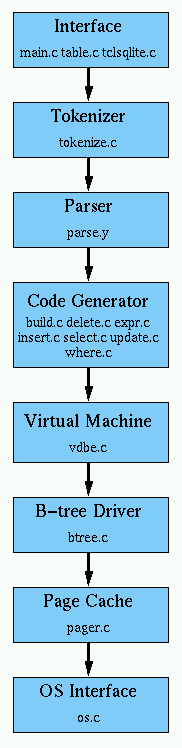
A block diagram showing the main components of SQLite and how they interrelate is shown at the right. The text that follows will provide a quick overview of each of these components.
Most of the public interface to the SQLite library is implemented by four functions found in the main.c source file. The sqlite_get_table() routine is implemented in table.c. The Tcl interface is implemented by tclsqlite.c. More information on the C interface to SQLite is available separately.
To avoid name collisions with other software, all external symbols in the SQLite library begin with the prefix sqlite. Those symbols that are intended for external use (in other words, those symbols which form the API for SQLite) begin with sqlite_.
When a string containing SQL statements is to be executed, the interface passes that string to the tokenizer. The job of the tokenizer is to break the original string up into tokens and pass those tokens one by one to the parser. The tokenizer is hand-coded in C. All of the code for the tokenizer is contained in the tokenize.c source file.
Note that in this design, the tokenizer calls the parser. People who are familiar with YACC and BISON may be used to doing things the other way around -- having the parser call the tokenizer. The author of SQLite has done it both ways and finds things generally work out nicer for the tokenizer to call the parser. YACC has it backwards.
The parser is the piece that assigns meaning to tokens based on their context. The parser for SQLite is generated using the Lemon LALR(1) parser generator. Lemon does the same job as YACC/BISON, but it uses a different input syntax which is less error-prone. Lemon also generates a parser which is reentrant and thread-safe. And lemon defines the concept of a non-terminal destructor so that it does not leak memory when syntax errors are encountered. The source file that drives Lemon is found in parse.y.
Because lemon is a program not normally found on development machines, the complete source code to lemon (just one C file) is included in the SQLite distribution in the "tool" subdirectory. Documentation on lemon is found in the "doc" subdirectory of the distribution.
After the parser assembles tokens into complete SQL statements, it calls the code generator to produce virtual machine code that will do the work that the SQL statements request. There are seven files in the code generator: build.c, delete.c, expr.c, insert.c select.c, update.c, and where.c. In these files is where most of the serious magic happens. expr.c handles code generation for expressions. where.c handles code generation for WHERE clauses on SELECT, UPDATE and DELETE statements. The files delete.c, insert.c, select.c, and update.c handle the code generation for SQL statements with the same names. (Each of these files calls routines in expr.c and where.c as necessary.) All other SQL statements are coded out of build.c.
The program generated by the code generator is executed by the virtual machine. Additional information about the virtual machine is available separately. To summarize, the virtual machine implements an abstract computing engine specifically designed to manipulate database files. The machine has a stack which is used for intermediate storage. Each instruction contains an opcode and up to three additional operands.
The virtual machine is entirely contained in a single source file vdbe.c. The virtual machine also has its own header file vdbe.h that defines an interface between the virtual machine and the rest of the SQLite library.
An SQLite database is maintained on disk using a B-tree implementation found in the btree.c source file. A separate B-tree is used for each table and index in the database. All B-trees are stored in the same disk file. Each page of a B-tree is 1024 bytes in size. The key and data for an entry are stored together in an area called "payload". Up to 236 bytes of payload can be stored on the same page as the B-tree entry. Any additional payload is stored in a chain of overflow pages.
The interface to the B-tree subsystem is defined by the header file btree.h.
The B-tree module requests information from the disk in 1024 byte chunks. The page cache is reponsible for reading, writing, and caching these chunks. The page cache also provides the rollback and atomic commit abstraction and takes care of reader/writer locking of the database file. The B-tree driver requests particular pages from the page cache and notifies the page cache when it wants to modify pages or commit or rollback changes and the page cache handles all the messy details of making sure the requests are handled quickly, safely, and efficiently.
The code to implement the page cache is contained in the single C source file pager.c. The interface to the page cache subsystem is defined by the header file pager.h.
In order to provide portability between POSIX and Win32 operating systems, SQLite uses an abstraction layer to interface with the operating system. The os.c file contains about 20 routines used for opening and closing files, deleting files, creating and deleting locks on files, flushing the disk cache, and so forth. Each of these functions contains two implementations separated by #ifdefs: one for POSIX and the other for Win32. The interface to the OS abstraction layer is defined by the os.h header file.
 Back to the SQLite Home Page
Back to the SQLite Home Page